1
Load balance over wide grid challange.
1.1
Grid ressources management
The main purpose of grids is the same than most
parallel and distributed systems are designed to achieve
: increase computation power by doing more and more
tasks at a time. So grid must deal with the same
problem. All computing potential can be used only when
job to ressource matching is efficient. But wide scale
grids are not an high integrated systems and the search
for available ressource is a new challange since it is
now difficult to know exactly how many jobs are running
all over the grid and where jobs are running.
1.2
Load monitoring and prediction.
Small parallel systems can rely upon a supervisor to
assign jobs as long as the centralised supervision task itself
does not need much computation power. Over a wide scale
grid, such a centralized process is a bottleneck. It must handle
istelf all job queries. When allocation is based upon actual
load average of each node, an iteration
of node average acquisition all over the grid is
required frequently (may be for each job submition).
This can't be achieve as the grid grows. The load
average time acquisition round may become longer than
a job and this process may use all the bandwith
available to the allocator.
One second aspect of a large scale grid is it is not
necessary made of identical nodes. One of its goal is to bring
available unused capacity of as many computers
connected to the internet as possible, each can be different and
then estimate the grid load capacity and locate
available CPU power is difficult. There aren't any
absolute hardware capacity benchmark (Hardware sellers
invents new benchmark as often as hardware releases) and
the best harware to run a task does not depend only on
the hardware spec but also on the task itself.
Last, knowing exactly the CPU usage map at a time is
not enough to perfectly assign jobs. The problem to
solve is : where will there enough CPU power available
during the job execution. This can be answered only if
jobs submition are planned and each job CPU usage is
predictable. Those two conditions will not be satisfied on
a grid targeted to share CPU power to more and more
users for a wide range of uses.
2
Adaptive load balancing
2.1
CAS for load balancing
Biologic systems are adaptives : their configuration
envolves to keep close to environnement changes
and deal with missing or bad
information. Information acquisition is limited
by sensors capacity and errors occurs during
perception processing (illusions, mirages).
But biologics by using try/error strategies can overpass
the sensors limitations and resolve problems from
incomplete and imperfect data. The optimum solution is rarely adopted
but a quite good one is very often found and simulated
biologic systems also succeed to without needing too
eavy computation.
As explained before, as the grid
grows, the grid state becomes more and more
difficult to acquire and process.
Since the perfect information needed for an optimal load balancing
is not available in real world cases, a
biomimetic system should be more efficient,
especialy where needed information is not
available or quite obsolete just after its
acquisition. But if it can't reach the perfect
balance it should be able to get to a good one,
and we hope it will not hang the grid with its
own process.
2.2
Biologic ressource finding models
Life is ressource finding : food, water, a safe place
to rest, reproductors... And some more litlle
things for a certain lifeform (oil, gold).
Well studies food searching :
Ants because, an ant is very simple, then is easy to
modelise.
Ant searching for food is exactly equivalent to our
problem : jobs searching for a CPU.
Food searching is undirected routing : the system
does not know were is the food, but it can find
where is the closest and the closest way to
it.
2.3
grant node selection and rehenforcement
Powerfull nodes are attractors.
Make loaded nodes repulsives.
Hybrids...
3
Distributed load balancing
Using a CAS strategy to resolve job to CPU mapping
may still overload the job submition if it stays on a
single allocator. A centralized one will need high query
serving capabilities and enough bandwith to relay all
jobs submition all over the grid and to recieve queries
of all users. There will never be enough bandwith
available to serve a grid as wide as the internet
itself.
Another big lack of a centralized allocator is that
when it stops running (malfunction, overlaod), all the
grid become unavailable.
3.2
neighbour relationship and grid topology
One solution is to distribute the load balancing
process itself all over the grid. As it is done by many
existing internet services (DNS, routing, P2P, ...),
queries may travel the grid from node to node
Each node is related to some other : it knows a few
node among all widely available and can
transfert job request to them.
Job query routing from node to node is not a problem
since like what is observed from real ants,
short path to CPU will become attractive quicker
than long one and then become more and more
attractive unless no more CPU is available at
the end of the short path...
3.3
uniform or non uniform load balancing
Since there is no more global supervisor, there is no
need of a global and absolute load estimator.
Each routing node may use its own. The only
requirement is that the load estimator should
disciminate overloaded nodes from others.
Each node may also use its own selector to apply
local heuristic if it is locally pertinent :
a subnetwork of stricly identical nodes may be Round
Robin load balanced...
- How to know entry points
- How to setup and maintain the grid topology.
4.1
The ant node selector
Each grant node is running this selection algorithm to
select a node among the known node at each job request :
- // variables
- myself : host that is running this processus
(i.e. this algorithm instance)
- activeNodeSet : list of nodes known by this
one, include myself when this node is not just a
request router.
- // inits active node set
- for each node from
activeNodeSet :
- // Job requests relaying main loop
- for each jobRequest from incoming job requests
- jobRequest.nodeStack.push(myself) // keep
track of node route from requester to runner.
- // select node by roulette wheel alogrithm regarding
active nodes marks
- totalMark = Sum(node.mark) from each node from
activeNodeSet
- acc=0
- select=random float in [0;1[
- i=0
- while acc <= select
- acc= acc +
activeNodeSet[i].mark/totalMark
- i = i + 1 // go to next node
- selectedNode= activeNodeSet[i-1]
- // give jobRequest to selected node
- if selectedNode == myself
- then // run job an reports its completion
- run jobRequest
- jobReport= (jobRequest, job
execution status, ....) // create report of job
execution
- myself.mark++
- jobReport.jobRequest.nodeStack.pop()
- // report job execution to parent node in
route path
- parentNode= jobReport.jobRequest.nodeStack.pop()
- parentNode.report( myself, jobReport )
- else // ask for selected node to handle the request
- selectedNode.relay( jobRequest )
When a node recieve a job execution report, it updates mark for
node that sent the report and relay the report to its parent
node in route path if any.
- // Job reports relaying main loop i.e implementation of
method report(reporter : node, jobReport :
report)
- reporter.mark++
- parentNode= jobReport.jobRequest.nodeStack.pop()
- if parentNode != null then
- parentNode.report( myself, jobReport )
Submit the same job query list to the same virtual
node network using different load balancing
methode :
- Round Robin : nodes are choose sequentialy one by
one.
- Random : nodes are totally randomly
affected.
- Best unloaded : heuristic of choosing the node with the
lowest running task count at the moment of the
job allocation.
- ant : our biomimetic method.
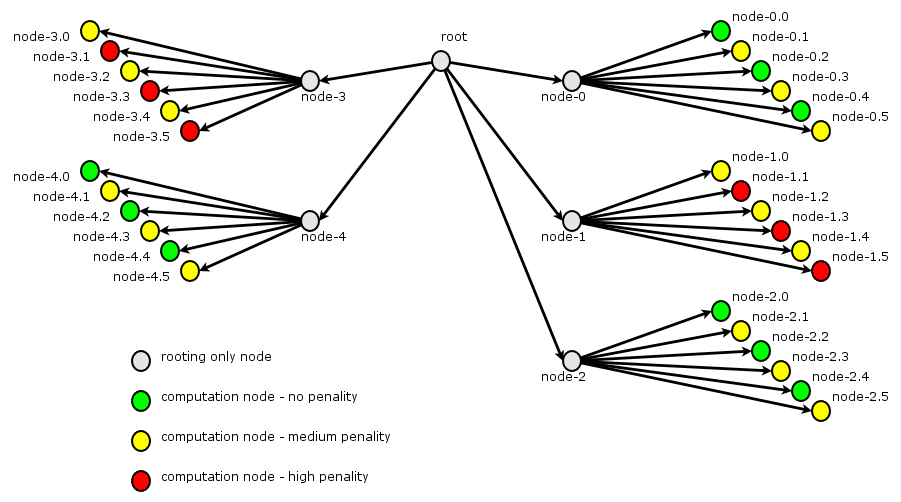
Virtual grant grid topology
Nodes have an intrinsec static performance. This is
emulated by forcing job sleeping with fixed value
delay
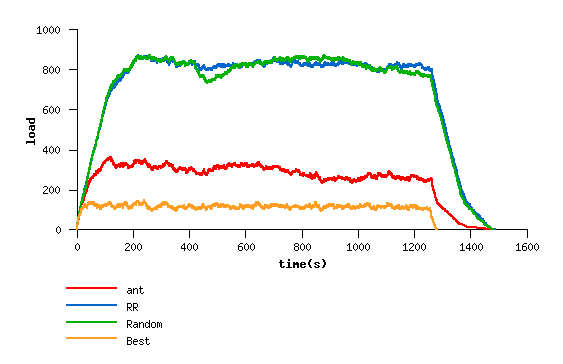
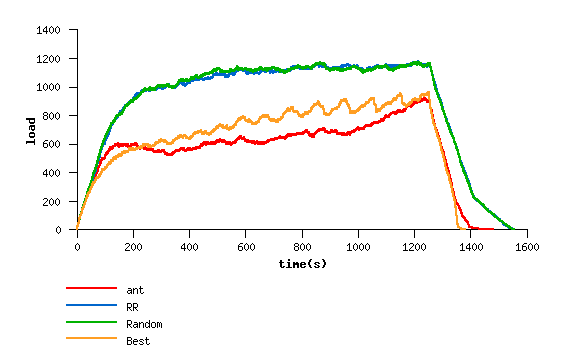
network overall load
Best heuristic load balance.
Ant load balance.
Round Robin load balance.
Random load balance
Here is shown the capacity of the grant allocation to
distribute load relating to nodes power. The
overall grid load is significatvely lesser than
with the "silly" distributions Random and RR.
But the grid exploration leads to many job
missaffected since the only way to estimate one
node capacity is to assign a job to it.
Since in this model, the best solution is simply to
use always the more powerfull nodes (jsut one of
them is enough), the grant allocator will never
be able to succeed.
The previous model is reused and another delay is
added relating to node load at job end.
network overall load
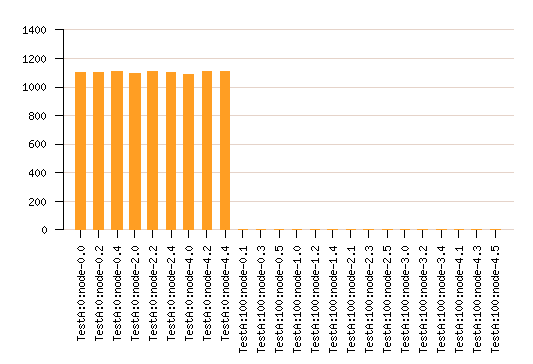
Best heuristic load balance.
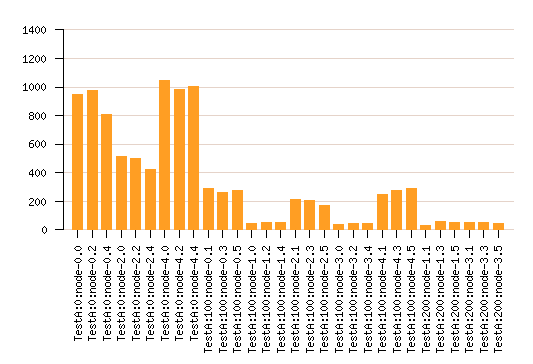
Ant load balance.
Round Robin load balance.
Random load balance
 Grant : world wide grid powered by virtual ants
Grant : world wide grid powered by virtual ants
 Adaptive cache management
Adaptive cache management
 Post message
Post message