2.1
approche biomimétique
Les algorithmes biomimétiques visent à simuler certains comportements
du vivant pour en extraire la capacité d'adaptation à des situations
changeantes et cela avec une perception parfois très limitée. Chaque être
vivant doit résoudre quotidiennement des situations difficilement prévisible
uniquement à l'aide d'information partielles. Le problème de la répartition
de charge dans un contexte hétérogène et généraliste (i.e. les tâches à
soumettre ne sont pas connues à l'avance donc il n'est pas possible de
planifier leur réalisation).
La grille ne devant pas être commandée par un point central critique, nous
nous interesserons plus particulièrement aux systèmes d'intelligences
collectives. De tels systèmes sont composés de nombreux éléments très
simples dont le comportement individuel ne présente aucun trait
d'intelligence voire même un certaine bêtise. Mais lorsqu'ils sont déployés
en nombres il émerge de leurs intéractions un comportement général qui
paraît intelligent, ou tout du moins suffisament évolué pour résoudre des
problème complexes [R1]. L'exemple le plus célèbre est la fourmilière : chaque
fourmis a un comportement suffisament simple pour être assez facilement modélisé
mais la colonie est capable de s'organiser pour affronter les aléas du monde
dans lequelle elle est plongée.
Tous les noeuds de la grille sont donc d'un point de vue fonctionnel
strictement identiques. Chacun est capable de prendre en charge le
traitement d'une tâche ou de relayer une requête vers un autre noeud. Chaque
noeud connaît un nombre limité de noeud voisin et la répartition de charge
agit localement pour déterminer à quel noeud confier une requête : soi-même
ou l'un des noeuds voisins connus. Evidemment le noeud choisi, voyant
arriver la requête fait de même et éventuellement dirige lui-même la demande
vers un troisième noeud, et ainsi de suite. Affecter une tâche à un noeud
dans un tel réseau s'apparente à du routage, on parcourt le réseau noeud par
noeud jusqu'à la destination avec la particulirité suivante : dans notre cas
la destination n'est pas connue à priori.
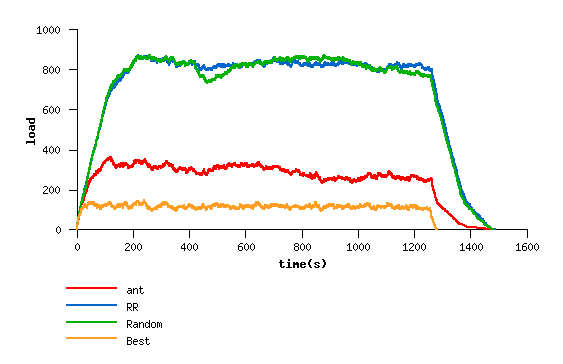
Le modèle des fourmis à la recherche de nourriture a déjà été appliqué
avec succès au routage adaptatif de paquets dans un réseau [R2]. Il
est transposable à la répartition de charge dès que celle ci peut également
être traitée comme un problème de routage. La non connaissance de la
destination pour chaque requête ne pose pas de problème puisque le modèle
utilisé répond au même critère en réalité : les sources de nourriture ne
sont connues pas connues des fourmis. Elles sont découvertes au fur et à
mesures et apparaissent ou disparaissent selon des événements non maîtrisés.
Le réseau de noeuds constitue l'environnement dans lequels les fourmis
sont plongées. Les fourmis à la recherche de nourritures sont les taches à
la recherche d'un processeur pour être éxécutées. Les fourmis parcours
d'abord au hasard le réseau jusqu'à aboutir à un noeud qui les accepte.
Lorsque le travail est terminé, le chemin ayant permis d'atteindre le noeud
est marqué. Ce marquage plus ou moins éphémère servira ensuite aux autres
fourmis à trouver un chemin menant à un processeur dans le réseau. Afin de
répartir efficacement la tache, le marquage doit être proportionnel à la
quantitié de nourriture, c'est à dire à la puissance de calcul disponible sur
un noeud. Si un noeud devient trop chargé, les taches-fourmis en reviennent
moins rapidement, le marquage vers ce noeud s'attenue et il apparaît alors
comme un moins bon candidat.
Tout le problème de la répartition de charge se réduit maintenant
à une gestion appropriée du marquage des liens inter-noeuds. Ce marquage
peut être élémentaire. Un incrément fixe pour chaque terminaison de tâche
est suffisant pour un renforcement des routes menant à de bons noeuds. Il
est toutefois possible d'accélérer l'apprentissage du réseau en utilisant un
marquage lié à la puissance constaté. Ainsi les incidences de situations
trompeuses alétoires (par exemple tâche très courte affecté à un mauvais
noeud) seront limitées. Le problème n'est pourtant pas trivial : il n'y a
pas d'indice de puissance absolue : il est déjà difficile de classer des
processeurs selon un axe de puissance unique. La mesure de la puissance
réelle disponible peut s'appuyer sur un ou plusieurs de ces critère :
- longueur de la route : cette mesure permet de privilégier le noeuds
les plus proche de soi (selon la topologie de routage qui peut être
différente de la topologie physique du réseau.)
- Taux d'occupation du processeur : cette information est accessible sur
la plupart des plateforme mais son acquisition est spécifique à chacune.
- Temps d'éxécution : il s'agit de la mesure la plus impartiale et la
plus significative pour l'utilisateur. Elle devrait toutefois être pondérée
par la quantité de code sinon toute tache un temps soi peu importante
signalerait avoir été éxécutée sur un mauvais noeud.
- Quantité de code éxécuté à l'issu de la tache : permet de reconsidérer
avantageusement les critères précédent. Ainsi le calcul de consommation des
ressources sera plus juste en tenant compte du travail réalisé. Toutefois se
posent les problème de l'unité (le nombre de bytecode java est un bon
candidat relativement neutre) et son acquisition requière que chacque tâche
soit instrumentée à cet effet.
La fonction d'évaluation n'a toutefois pas besoin d'être totalement
absolue sur tout le réseau, il suffit qu'il le soit pour tous les éléments
pris en compte lors du routage d'une tâche. La fonction d'évaluation peut
donc être locale à chaque noeud routeur si elle est appliquée de façon
identique à tous les noeuds connus au niveau d'un noeud routeur.
De plus ces multiples critères d'évaluation permettent d'aller plus
loin qu'une simple optimisation de l'affectation des noeuds. Il est aussi
possible d'optimiser la topologie du réseau par la recherche des meilleurs
chemins d'accès à la puissance de calcul.
Chaque noeud ne connais qu'un certain nombre d'autres noeuds
auquel il est capable de relayer des requêtes. Cette relation de
voisinage constitue une topologie qui selon ces caractéristiques aura
une certaine influance sur les perforamances (robustesse, réactivité,
...) de la grille.
- arbres : Si l'arbre est bien balancé, cette topologie permet
d'atteindre chaque noeud de façon unique avec un nombre d'intermédiaires
maitrisé. Cependant la défaillance d'un seul intermédiaire coupe l'accès
à toute une branche de l'arbre. De plus le noeud racine est un goulot
d'étranglement potentiel puisque il doit relayer toutes les requêtes.
- réseau maillé : un réseau maillé, s'il peut augmenter
considérablement la combinatoire d'accès au noeud apporte une certaine
robustesse dès qu'il existe plusieurs noeuds d'accès ainsi que
plusieurs chemins possibles pour atteindre chaque noeud. De cette façon
les incidences de la défaillance d'un noeud sont limitées aux tâches en
cours d'execution sur celui-ci.
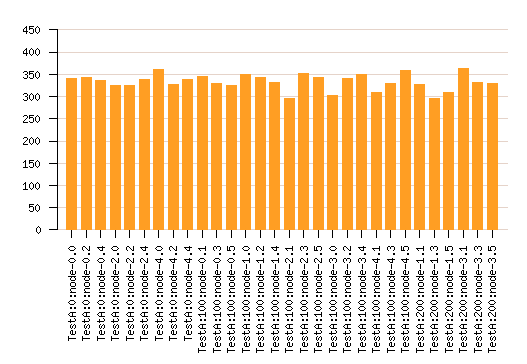
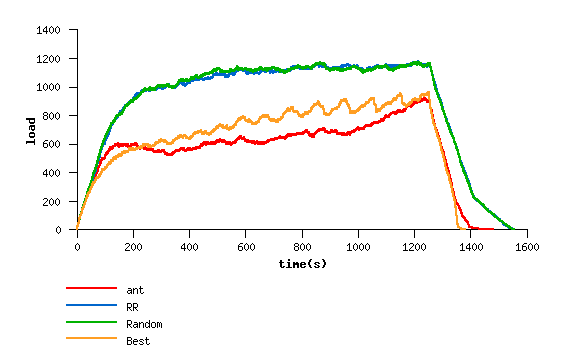
 Grant : world wide grid powered by virtual ants
Grant : world wide grid powered by virtual ants
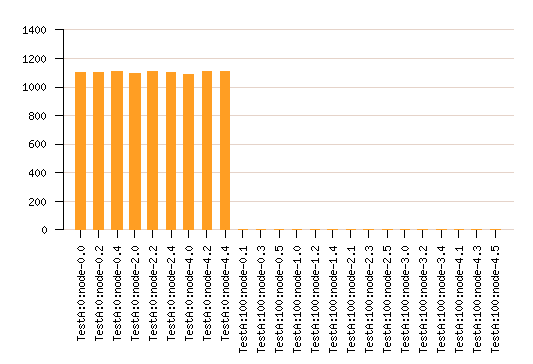
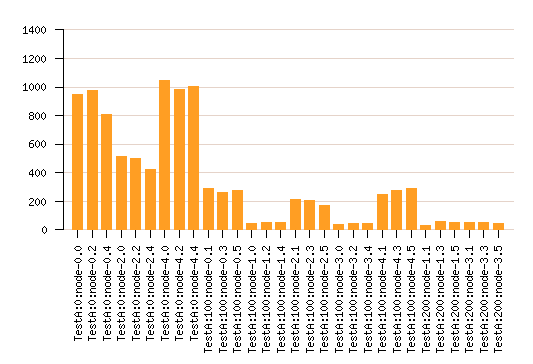
 Adaptive cache management
Adaptive cache management
 Post message
Post message